
1월 첫번째 주 AI 뉴스
January 3, 2024

이번주 AI 뉴스 📰

뉴욕 타임즈, OpenAI 및 Microsoft에 저작권 침해 소송 제기
저작권 침해 소송 제기: 뉴욕 타임즈가 OpenAI와 Microsoft를 저작권 침해로 소송. 이들 회사는 뉴욕 타임즈의 수백만 기사를 사용하여 경쟁 챗봇을 훈련시켰다고 주장.
저작권 보호 요구: 불법 복제 및 사용에 대한 수십억 달러의 법적, 실제적 손해 배상을 요구. 또한, 저작권이 있는 자료를 사용한 챗봇 모델과 훈련 데이터의 파기를 요구.
미디어와 AI 기술의 충돌: 뉴욕 타임즈는 AI 시스템이 경쟁자가 될 수 있다고 주장하며, AI가 생성한 콘텐츠가 기존 저널리즘을 대체할 위험이 있음을 강조.

대법원장 로버츠, 법정에서 AI의 가능성과 위험성 지적
AI의 법적 활용과 위험성: 존 로버츠 대법원장이 연례 보고서에서 법정에서 AI의 긍정적 역할과 위협에 대해 언급. AI 사용 시 주의와 겸손이 필요하다고 강조.
AI의 영향력과 도전: 로버츠 대법원장은 법률 연구에 AI가 없이는 상상하기 어려울 것이라고 지적. 동시에 개인 정보 침해와 법의 인간화 저하의 위험을 언급.
인간 판단의 필요성 강조: 로버츠 대법원장은 법적 결정은 여전히 인간 판단을 필요로 하며, 많은 사람들이 기계보다 인간을 신뢰한다고 결론지음. AI가 현재 정보에 기반을 두고 있어 새로운 법적 영역에서의 발전을 이끌 수는 없다고 언급.

가짜 법정 사례 인용: 도널드 트럼프 전 변호사인 마이클 코언이 연방 판사 앞에서 AI가 생성ㅌ한 가짜 법정 사례를 인용한 것을 인정. 구글의 Bard를 '초강력 검색 엔진'으로 오인하고 사용.
법적 문서의 오류와 결과: 코언은 과거 혐의로 유죄를 인정하고 징역 후 보호 관찰 중인데, 연방 판사에게 보호 관찰 기간 단축을 요청하는 동안 가짜 사례를 포함시킴. 이에 대해 미국 지방 판사 제시 퍼먼은 해당 사례가 실재하지 않음을 지적하고 코언의 변호사에게 설명을 요구.
AI 기술 사용의 위험성: 코언은 법정에 오해를 불러일으키려는 의도가 없었다고 밝히며, Google Bard를 사용한 것은 인식하지 못한 실수였다고 해명. 이 사건은 AI 생성 콘텐츠가 법적 문맥에서도 실수를 유발할 수 있음을 보여줌.
이번주 AI 논문 📝

Astraios: 대규모 언어 모델을 위한 효율적인 지시어 조정 기법
PEFT와 FFT의 비교: 대규모 언어 모델(16억 파라미터)의 효율적 조정을 위해 Astraios와 28개의 OctoCoder 모델이 소개되었으며, 다양한 스케일에서 PEFT와 FFT의 성능을 비교함.
효과적인 PEFT 방법: 다양한 작업과 데이터셋에서 FFT가 일반적으로 가장 높은 성능을 보였으며, PEFT 방법은 모델 스케일에 따라 크게 달라짐.
모델의 강인성과 보안: 큰 모델이 강인성이 떨어지고 보안 문제가 있을 수 있으며, 파라미터 업데이트와 성능 간의 관계를 탐색함.

새로운 임베딩 방법: 1천 단계 미만의 훈련과 합성 데이터만을 사용하여 고품질 텍스트 임베딩을 얻는 새롭고 간단한 방법을 소개함.
복잡한 파이프라인 불필요: 기존 방법과 달리 복잡한 훈련 파이프라인이나 수작업으로 수집된 데이터셋에 의존하지 않고, 다양한 언어로 수십만 임베딩 작업을 위한 합성 데이터를 생성함.
높은 벤치마크 성능: 라벨이 없는 데이터만 사용하여도 높은 벤치마크 성능을 달성하며, 합성 데이터와 라벨 데이터를 혼합하여 미세 조정 시 최신 성과를 달성함.

교육에서 MLLMs의 역할: 다중 모달 대규모 언어 모델(GPT-4V 등)의 도입이 과학 교육에서 맞춤형, 상호 작용적 학습 환경을 풍부하게 함. (MLLMs = Multimodal Large Language Model)
다양한 응용 가능성: MLLMs는 콘텐츠 생성부터 학습 지원, 과학 실천 능력 증진, 평가 및 피드백 제공에 이르기까지 다양하게 활용될 수 있음.
기술 도입의 균형 필요: 데이터 보호 및 윤리적 고려사항이 부각되면서 교육자의 역할을 보완하고 AI를 효과적으로 사용하기 위한 균형 잡힌 접근이 필요함.
이번주 AI 프로덕트 📦

텍스트 생성 모델에 대한 새로운 접근: CosMo는 언어 모델을 단일 모달 텍스트 처리와 다중 모달 데이터 처리 부분으로 구분하여 대비 손실을 도입함.
성능 향상과 매개변수 감소: CosMo는 텍스트와 시각 데이터 작업에 대한 성능을 향상시키면서 학습 가능한 매개변수를 크게 줄임.
HowtoInterlink7M 데이터셋: 긴 텍스트 비디오 데이터셋의 부족을 해결하기 위해, 포괄적인 캡션을 포함한 HowtoInterlink7M 데이터셋을 소개함.
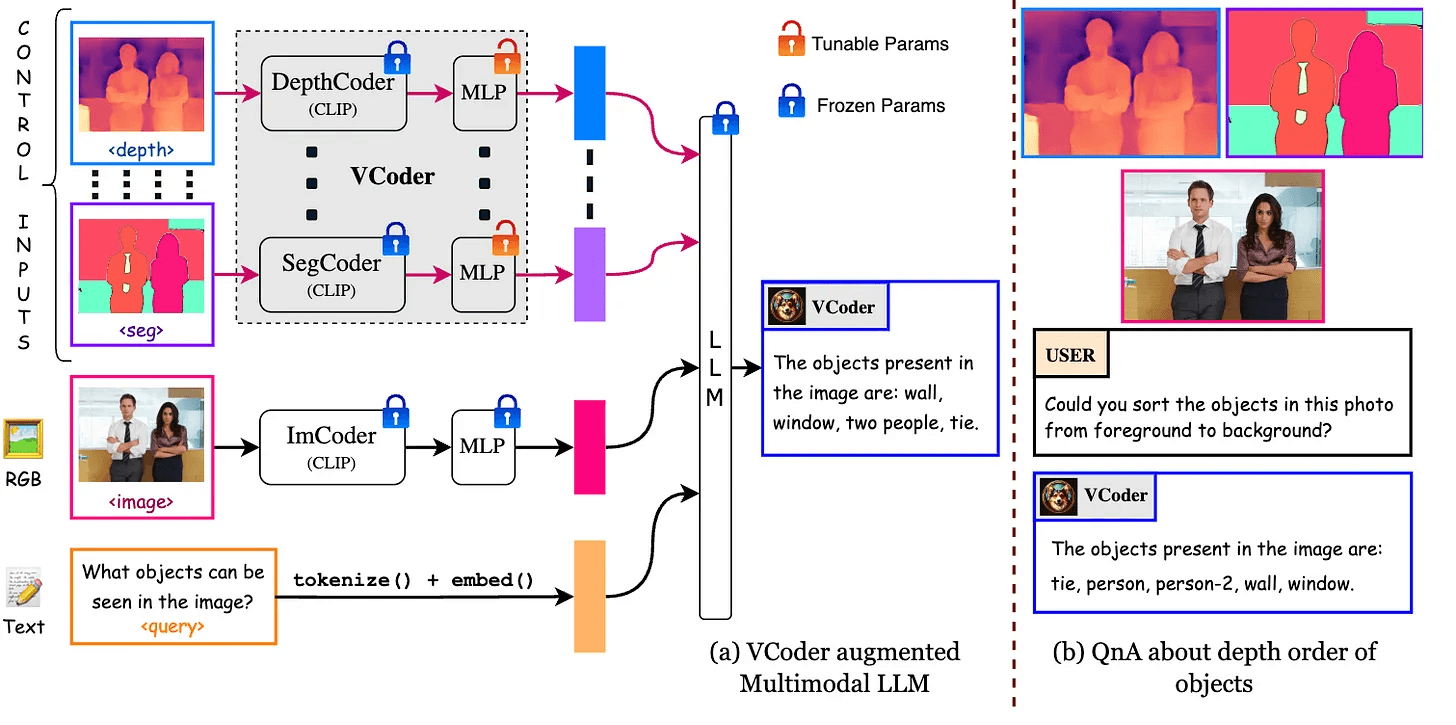
VCoder: 멀티모달 대규모 언어 모델을 위한 다용도 시각 인코더
시각 인식 문제의 해결: 멀티모달 대규모 언어 모델(MLLM)이 이미지 내 객체를 식별하거나 계산하는 데 어려움을 겪는 문제를 해결하기 위해 VCoder 제안.
COST 데이터셋 개발: COCO 이미지와 기존 시각 인식 모델의 출력을 활용하여 객체 인식 작업 훈련 및 평가를 위한 COCO Segmentation Text (COST) 데이터셋을 개발함.
VCoder의 인식 능력: 실험적 증거를 통해 VCoder가 기존 멀티모달 LLMs, GPT-4V를 포함하여 객체 수준 인식에서 우수한 성능을 보임을 입증함.
By BetaAI
© 2023