
11월 두번째 주 AI 뉴스
November 8, 2023

이번주 AI 뉴스 📰

openAI의 첫 컨퍼런스 종료, chatGPT 대규모 업데이트 예정
사용자 정의 GPT의 등장: OpenAI는 개인의 목적에 맞게 특화된 인공지능 기술 버전 구축을 허용하며, 새로운 GPT 앱 스토어를 통해 이러한 챗봇들을 공유하거나 찾을 수 있게 될 예정
AI의 비즈니스 활용성 증대: 이 특수 목적 GPT는 비즈니스의 자동화된 작업을 위한 대화형 인터페이스 제공으로, 기업들에게 매력적인 옵션이 될 것으로 보임.
GPT-4 Turbo의 혁신: OpenAI는 새로운 대규모 언어 모델인 GPT-4 Turbo를 발표하였으며, 이는 더 크고 복잡한 프롬프트를 처리하고 이미지 입력을 받아들이는 기능을 가지고 있음.

스타일 튜닝의 진화: Midjourney는 사용자들이 일관된 스타일의 AI 생성 이미지를 생산할 수 있도록 새로운 스타일 튜너 기능을 업데이트함.
효율적인 스타일 적용: 이제 사용자들은 다양한 스타일 중에서 선택하고 이를 코드로 저장하여 미래의 모든 작업에 적용함으로써 같은 미적 계열을 유지할 수 있음.
창의적 프로젝트의 통일성: 이 기능은 기업, 브랜드, 그룹 창작 프로젝트에 있어 일관된 스타일로 작업하는 데 큰 도움이 될 것.
일론 머스크의 xAI, 새로운 AI 챗봇 'Grok' 공개
Grok의 혁신적 기능: Elon Musk가 이끄는 AI 스타트업 xAI에서 Grok을 공개했는데, 실시간 정보를 제공하는 능력이 특징이며, 전통적인 AI 대응 방식에서 벗어나 더 인간적이고 참여적인 대화 스타일을 선보임.
Grok-1의 고급 성능: Grok-0에서 발전된 Grok-1은 인간 평가 코딩 작업에서 63.2%, MMLU에서 73%를 달성하며, 기존 모델들을 능가하는 성능을 보임.
xAI의 협력과 인프라: xAI는 Google's DeepMind, Microsoft와 같은 유명 AI 연구 기관과 협력하며, Kubernetes, Rust, JAX 기반의 맞춤형 교육 및 추론 스택으로 Grok의 인프라를 구축함.
이번주 AI 논문 📝
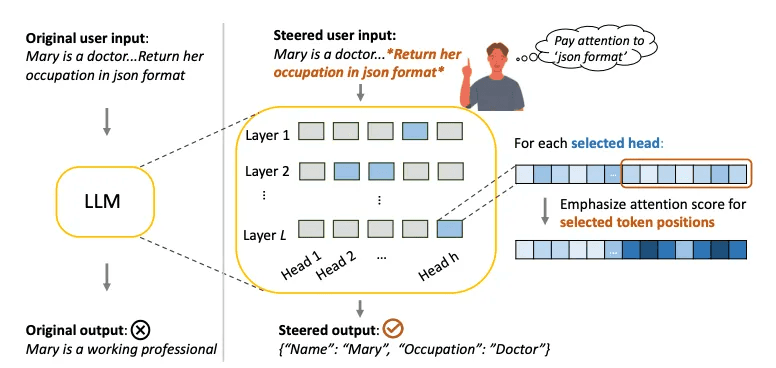
텍스트 스타일의 미묘함 활용: 사용자가 강조하고 싶은 정보에 대해 LLM(Large Language Models)이 더 집중할 수 있도록 하는 PASTA(Post-hoc Attention STeering Approach) 방법론을 소개함.
주의력 재조정 기능: PASTA는 사용자가 지정한 부분에 모델의 주의를 집중시키기 위해 주의 헤드의 작은 부분 집합을 식별하고 그에 대한 정밀한 주의 재조정을 적용함.
성능 향상 입증: 실험을 통해 PASTA가 사용자 지시 사항을 따르거나 사용자 입력에서 새로운 지식을 통합하는 LLM의 능력을 크게 향상시킬 수 있음을 보여줌, 예를 들어 LLAMA-7B의 평균 정확도를 22% 향상시킴.
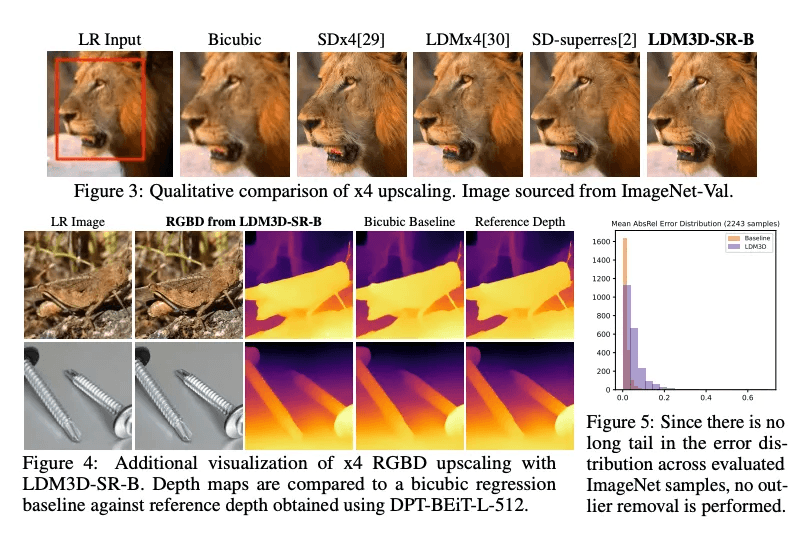
3D VR 개발을 위한 모델 제안: 잠재 확산 모델이 시각적 결과물의 생성 및 조작에서 최신 기술로 입증되었으나, RGB와 함께 뎁스를 생성하는 것은 여전히 제한적임을 극복하기 위해 LDM3D-VR을 소개함.
파노라마 및 고해상도 지원: LDM3D-VR은 텍스트 프롬프트를 기반으로 파노라마 RGBD를 생성하고 저해상도 입력을 고해상도 RGBD로 업스케일링하는 LDM3D-pano와 LDM3D-SR 모델을 포함함.
모델 평가 및 데이터셋 활용: 이 모델들은 파노라마/고해상도 RGB 이미지, 깊이 지도 및 캡션을 포함하는 데이터셋에서 사전 훈련된 모델을 기반으로 미세 조정되었으며, 기존 관련 방법과 비교하여 평가됨.
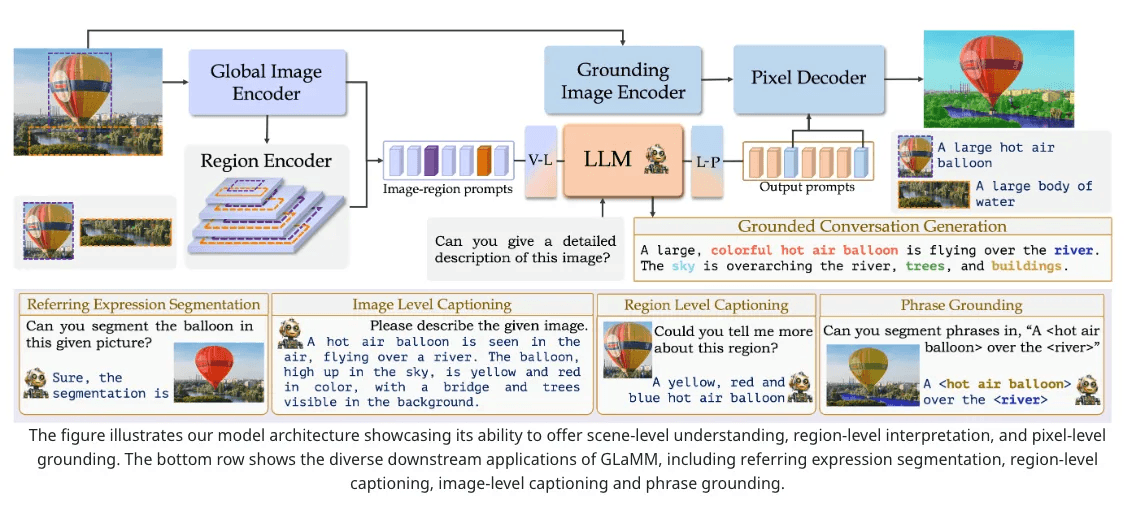
GLaMM: 픽셀 레벨에서 객체를 구별하는 대규모 다중모달 모델
객체 분할과 언어 반응의 통합: Grounding LMM (GLaMM)은 객체 분할 마스크와 연계된 자연스러운 언어 반응을 생성하는 첫 번째 모델로, 대화 중 나타나는 객체들을 식별하는 능력을 가짐.
입력에 대한 유연성: GLaMM은 텍스트와 시각적 프롬프트(관심 영역) 모두를 입력으로 받아들이며, 사용자가 텍스트와 시각적 도메인에서 다양한 수준의 세밀함으로 모델과 상호작용할 수 있게 함.
평가 프로토콜 및 데이터셋 개발: 시각적으로 구체화된 대화 생성을 위한 새로운 평가 방법과 대규모로 자연 장면에서 밀접하게 구체화된 개념이 필요한 Grounded Conversation Generation (GCG) 작업을 소개하며, 이를 위해 7.5M 개의 독특한 개념이 810M 영역에 걸쳐 분할 마스크와 함께 구체화된 Grounding-anything Dataset (GranD)을 제안함.
이번주 AI 프로덕트 📦

CogVLM: 시각적 전문성이 추가된 사전 훈련된 언어 모델
시각 언어 기능의 깊은 융합: CogVLM은 사전 훈련된 언어 모델과 이미지 인코더 간의 간극을 연결하는 훈련 가능한 시각 전문가 모듈을 통해 시각 언어 기능의 깊은 융합을 가능하게 하는 강력한 시각 언어 기반 모델
다중모델 벤치마크에서의 최신 성능: CogVLM-17B는 NoCaps, Flicker30k 캡셔닝, RefCOCO 시리즈, Visual7W 등 10가지 고전적인 다중모달 벤치마크에서 최신 성능을 달성하고, VQAv2, OKVQA, COCO 캡셔닝 등에서 2위를 기록함.
코드 및 체크포인트 공개: CogVLM의 코드와 체크포인트는 공식 웹사이트를 통해 공개되어 있음.
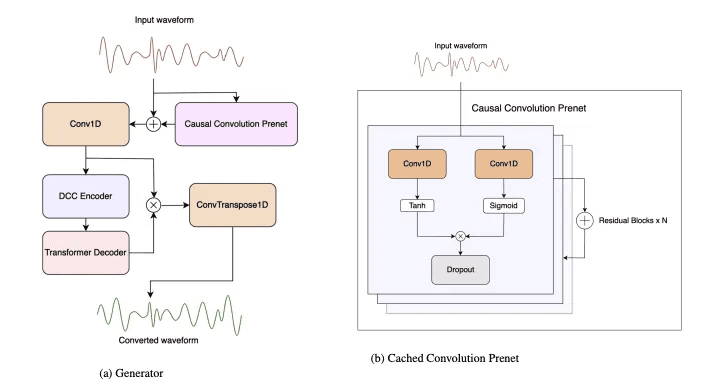
저지연 실시간 음성 변환 모델 개발: LLVC (Low-latency Low-resource Voice Conversion)는 16kHz 비트레이트에서 20ms 미만의 지연 시간을 가지며, 소비자 CPU에서 실시간의 약 2.8배 빠른 속도로 실행됨.
첨단 아키텍처 적용: LLVC는 생성적 적대 신경망 아키텍처와 지식 증류를 사용하여 이러한 성능을 달성함.
오픈 소스 제공: LLVC는 현재까지 공개된 음성 변환 모델 중에서 가장 낮은 리소스 사용과 가장 낮은 지연 시간을 달성하며, 샘플, 코드, 사전 훈련된 모델 가중치를 제공함.
By BetaAI
© 2023