
11월 첫번째 주 AI 뉴스
November 1, 2023

이번주 AI 뉴스 📰

행동 수칙의 도입: G7 국가들은 인공지능 기술의 위험과 잘못된 사용을 완화하기 위해 기업들을 대상으로 한 행동 수칙을 도입하기로 합의.
안전한 AI의 활용 강조: 행동 수칙에 포함된 11항목의 수칙은 안전하고 신뢰할 수 있는 AI를 전 세계적으로 홍보하며, 최첨단 AI 시스템을 개발하는 조직에 자발적인 지침을 제공할 것.
사용자 보호와 투명성 강조: AI 제품 출시 후에도 회사들은 미스 사용 패턴을 해결하고, AI 시스템의 능력, 한계 및 사용에 대한 공개 보고서를 게시해야 함.

Google Brain 공동 창립자, “'AI 멸망 주장'은 기술 기업의 거짓말.”
AI 위험성에 대한 오해: Google Brain 공동창립자인 Andrew 교수는 주요 기술 기업들이 'AI가 인류를 멸망시킨다'는 주장을 과장하며 홍보하고 있다고 지적함.
AI 라이선스 제안의 위험성: Ng 교수는 AI를 라이선스화하는 정책 제안은 혁신을 억제하며, 몇몇 대형 기술 회사들은 오픈 소스 AI와 경쟁하는 것을 원하지 않기 때문에 AI 위험성을 과장하고 있다고 지적.
적절한 규제의 중요성: Ng 교수는 AI 규제의 필요성은 인정하지만, 많은 국가들이 추구하는 방향에 대해 우려를 표현하며, '좋은' 규제 중 하나로 기술 회사들의 투명성을 강조함.

마이크로소프트 CEO, "Copilot AI 는 새로운 '시작' 버튼"
Windows Copilot 중심의 AI 전략: 마이크로소프트는 AI를 중심으로 두며 Windows Copilot를 새로운 '시작' 버튼으로 간주함.
새로운 사용자 경험의 변화: Nadella CEO는 Copilot를 통해 사용자의 의도를 표현하고 앱을 쉽게 찾을 수 있으며 사용자 습관에 변화를 가져올 것이라고 주장.
Copilot의 가능성: Copilot는 앱을 실행하는 방법이거나 앱을 제안하는 방법일 수 있으며, 이는 Windows에서 원하는 작업을 도와주는 더 풍부한 방법으로 여겨짐.
이번주 AI 논문 📝
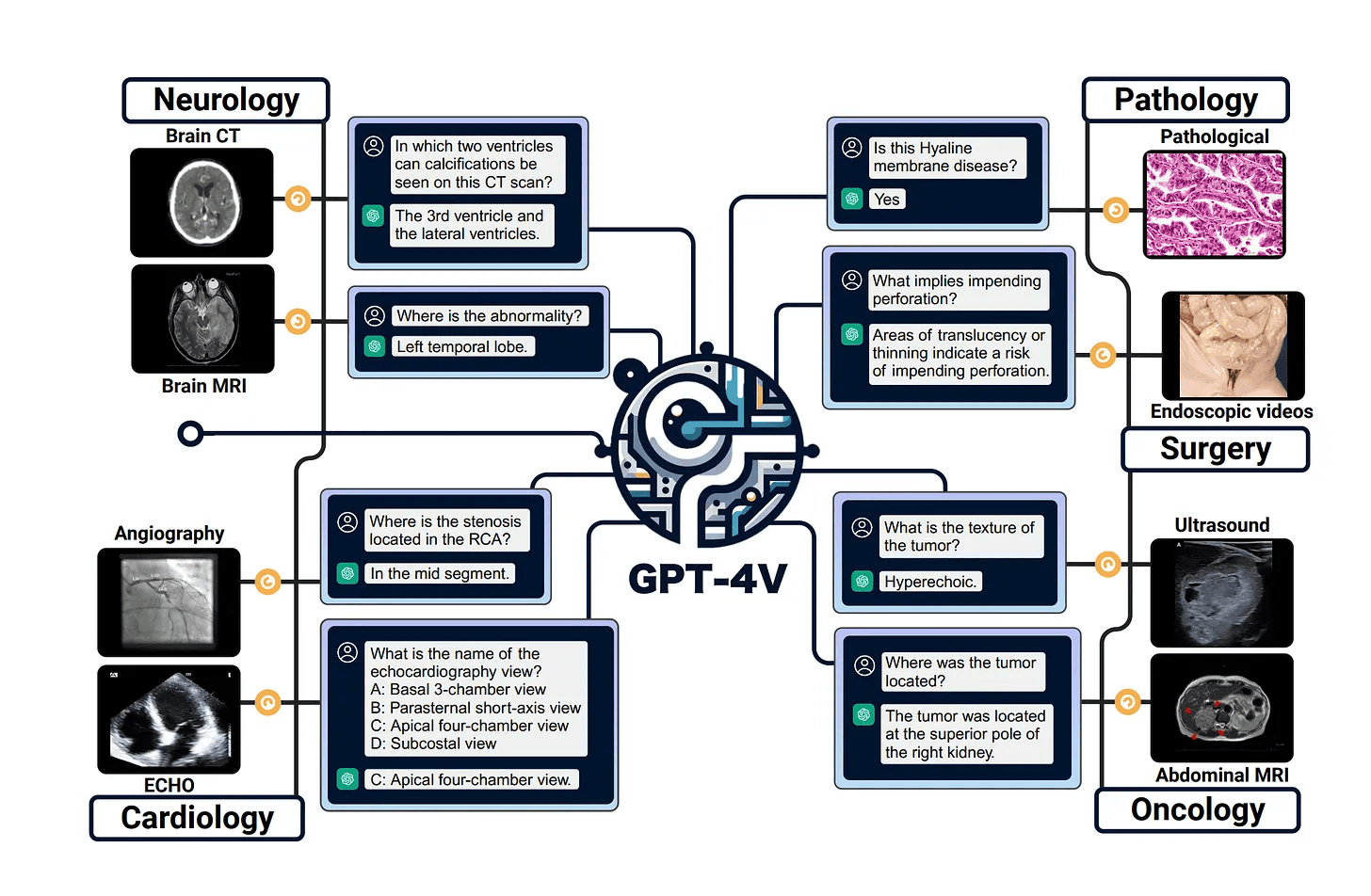
의료 분야에서의 다중모달 ChatGPT 실험: GPT-4V의 실험적 연구
GPT-4V의 시각적 질문 응답 능력 평가: 본 연구에서는 GPT-4V의 시각적 질문 응답(VQA) 능력을 철저히 평가하며, 병리학과 방사선학 데이터셋을 활용해 실험을 진행함.
신뢰성 부족으로 진단용으로 미추천: GPT-4V의 정확도 점수를 바탕으로 실제 진단에는 비추천하며, 진단 의료 질문에 대한 부정확하고 최적이 아닌 정확도를 보여줌.
GPT-4V의 의료 VQA에서의 한계 강조: 연구에서는 GPT-4V의 의료 VQA에서의 7가지 독특한 양상을 설명하며, 이 복잡한 분야에서의 제약사항을 강조함.
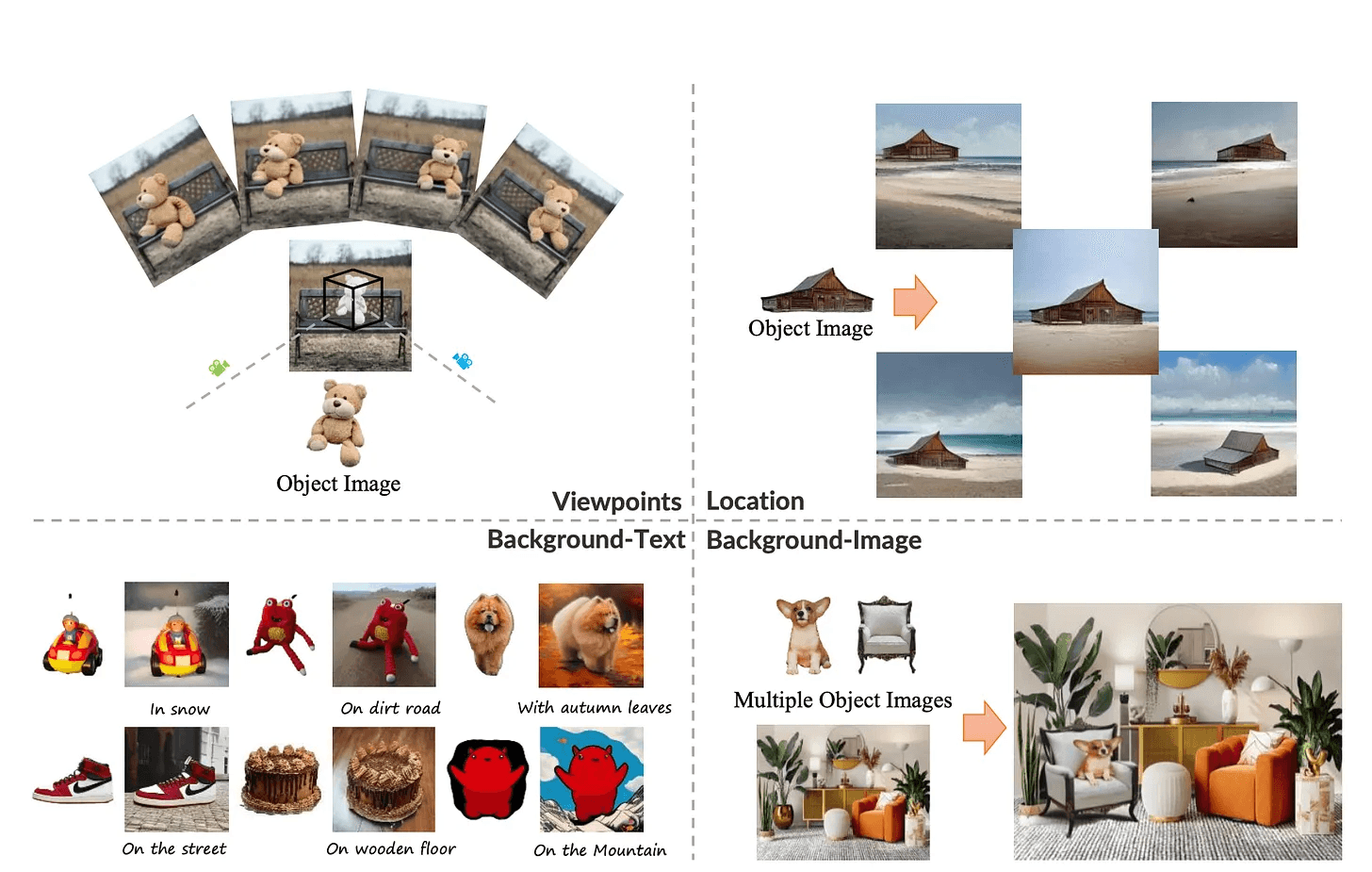
CustomNet: 글로 다양한 각도의 이미지를 생성해주는 기술
더 나은 그림 만들기: CustomNet은 글을 보고 그림을 그리는 기술을 향상시켜, 우리가 원하는 물건이 자연스럽게 그림 속에 들어가 보이게 도와줌.
우리의 선택대로 조절 가능: 글로 물건의 위치나 배경을 정할 수 있어, 우리가 원하는 대로 그림을 조절할 수 있게 해줌.
더 다양한 그림 생성: 이 기술은 여러 각도에서 물건을 볼 수 있게 해주어, 더 다양하고 실제 같은 그림을 만들 수 있게 도움.
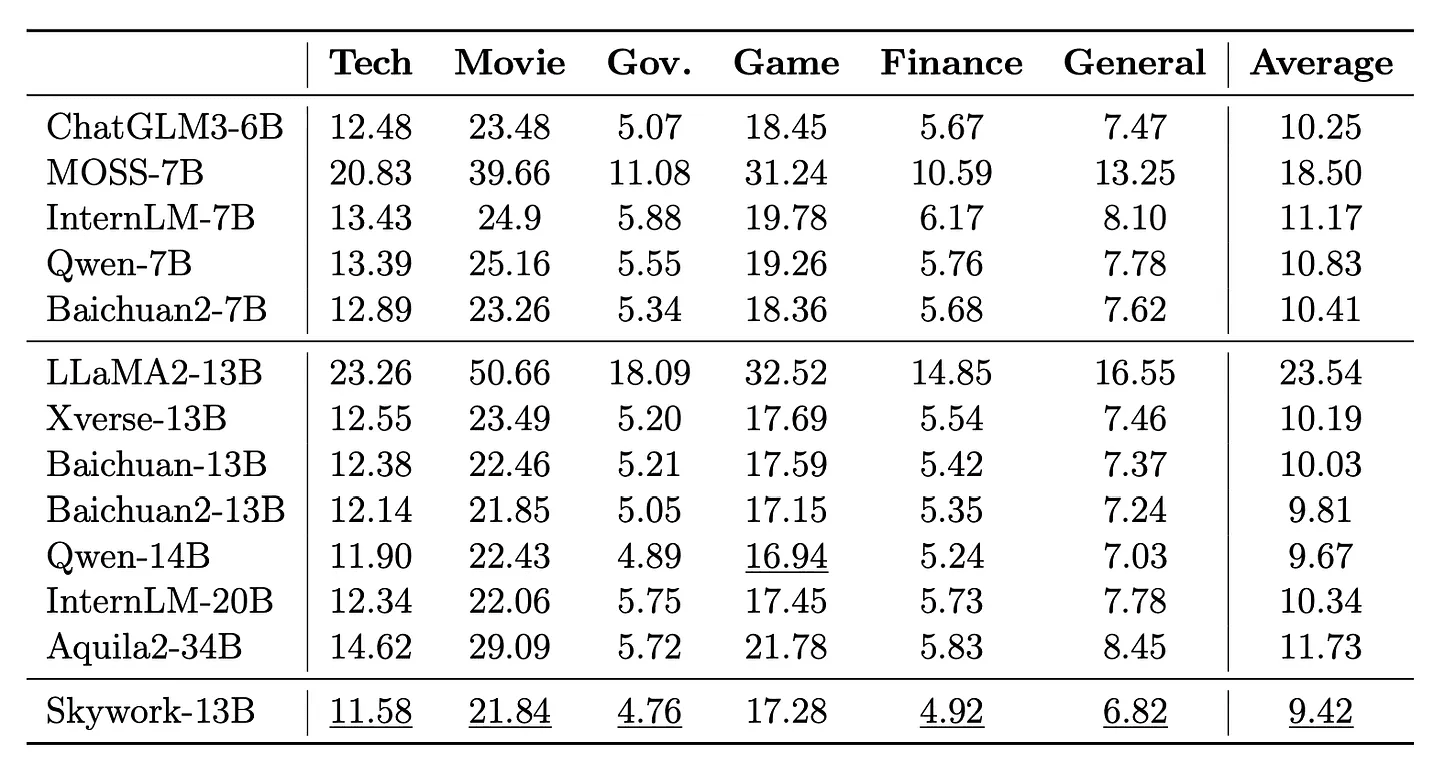
Skywork: 더 개방적인 이중 언어 기반 모델 소개
양방향 언어 학습: Skywork-13B는 영어와 중국어 텍스트로 구성된 대량의 데이터를 학습하여 두 언어 모두에 대한 처리 능력을 갖춘 모델을 제시함.
전문 분야 향상 훈련: 일반적인 학습과 전문 분야 향상 훈련 두 단계를 거쳐 모델의 성능을 높이고 다양한 분야에서 중국어 모델링의 최고 성능을 달성함.
향후 연구 촉진: Skywork-13B와 SkyPile 코퍼스(corpus) 일부를 공개함으로써, 높은 품질의 언어 모델에 대한 접근을 더욱 공개화하고 향후 연구를 촉진하고자 함.
이번주 AI 프로덕트 📦

VideoCrafter1: 고품질 비디오 생성을 위한 오픈 디퓨전 모델
비디오 생성의 새로운 지평: VideoCrafter1은 텍스트를 비디오(T2V)와 이미지를 비디오(I2V)로 변환하는 두 가지 디퓨전 모델을 제시, 상업용 툴에 버금가는 고품질 비디오 생성 가능.
T2V와 I2V 모델의 차별성: T2V (text2video)모델은 주어진 텍스트를 기반으로 실제적이고 영화 같은 품질의 비디오를 생성, 반면 I2V (image2video) 모델은 참조 이미지의 내용, 구조, 스타일을 유지하면서 비디오 클립을 생성함.
오픈소스의 선봉장: 이 모델들은 첫 오픈소스 기반의 I2V 기초 모델로, 커뮤니티 내 기술 발전에 중요한 기여를 할 것으로 기대됨.

모델의 개방과 훈련: GLM-130B는 1300억 개의 매개변수를 가진 이중(영어와 중국어) 언어 사전 훈련 모델로, GPT-3(davinci)와 같거나 더 좋은 성능을 내는 1000억 규모의 모델을 오픈소스로 공개함.
기술적 도전과 개선: 이 과정에서 여러 기술적, 엔지니어링적 어려움을 마주했으며, 특히 손실 증가와 발산 문제를 해결함.
성능과 확장성: GLM-130B는 다양한 인기 있는 영어 벤치마크에서 GPT-3 175B(davinci)를 크게 앞섰으며, 중국어 모델 ERNIE TITAN 3.0 260B를도 능가함.
By BetaAI
© 2023