
9월 첫번째 주 AI 뉴스
August 30, 2023

이번주 AI 뉴스 📰

기업 수준의 보안 및 개인정보 보호: ChatGPT 엔터프라이즈는 SOC 2에 준수하며, 데이터를 암호화하여 저장 및 전송하고, 고객 데이터로 모델을 훈련하지 않음.
확장 가능한 배포: 대량 회원 관리, SSO, 도메인 검증, 사용량 분석 대시보드 등의 기능을 관리 콘솔에서 제공함.
강화된 기능: GPT-4에 무제한으로 접근 가능하며, 토큰 context 창이 최대 32k까지 확장되고, 고급 데이터 분석 기능도 제공됨.

Microsoft CEO, AI는 ‘인간의 통제’ 가 필요 주장
인간의 통제 필요성: 마이크로소프트의 대표인 브래드 스미스는 인공지능이 무기화될 수 있으므로 인간의 통제가 필요하다고 주장함. =
AI의 위험성 경고: OpenAI, Google의 DeepMind, 마이크로소프트 등 다양한 기술 리더들은 AI가 인류 멸종의 위험성을 가지고 있다고 경고함. 테슬라의 일론 머스크와 애플 공동창업자 스티브 워즈니악도 AI의 발전을 일시 중단해야 한다고 주장함.
일자리에 미치는 영향: AI의 빠른 성장으로 인해 많은 직업이 위협을 받을 수 있다고 경고되고 있음. 그러나 마이크로소프트 대표는 AI는 인간의 일을 대체하는 것이 아니라 보완하는 도구라고 지적함.

일론 머스크와 마크 주커버그, 미국 상원의 첫 AI 포럼에 참가 예정
참가자 명단: 테슬라와 SpaceX의 CEO 일론 머스크, 메타(구 페이스북)의 CEO 마크 주커버그, 마이크로소프트의 사티아 나델라, 알파벳의 순다르 피차이, OpenAI의 샘 알트만, NVIDIA의 젠슨 황 등이 참가할 예정.
포럼 목적: 미국 상원의 다가오는 AI 관련 포럼은 인공지능을 규제하는 방법에 대해 논의할 것입니다. 이 포럼은 AI 산업을 규제하기 위한 법안을 작성하는 근거가 될 예정.
비판과 의문: 상원에서 일반적으로 큰 정책 법안은 관할 위원회를 통해 발전되지만, 이번에는 다르게 접근하고 있어 일부는 의문을 제기하고 있음.
이번주 AI 논문 📰
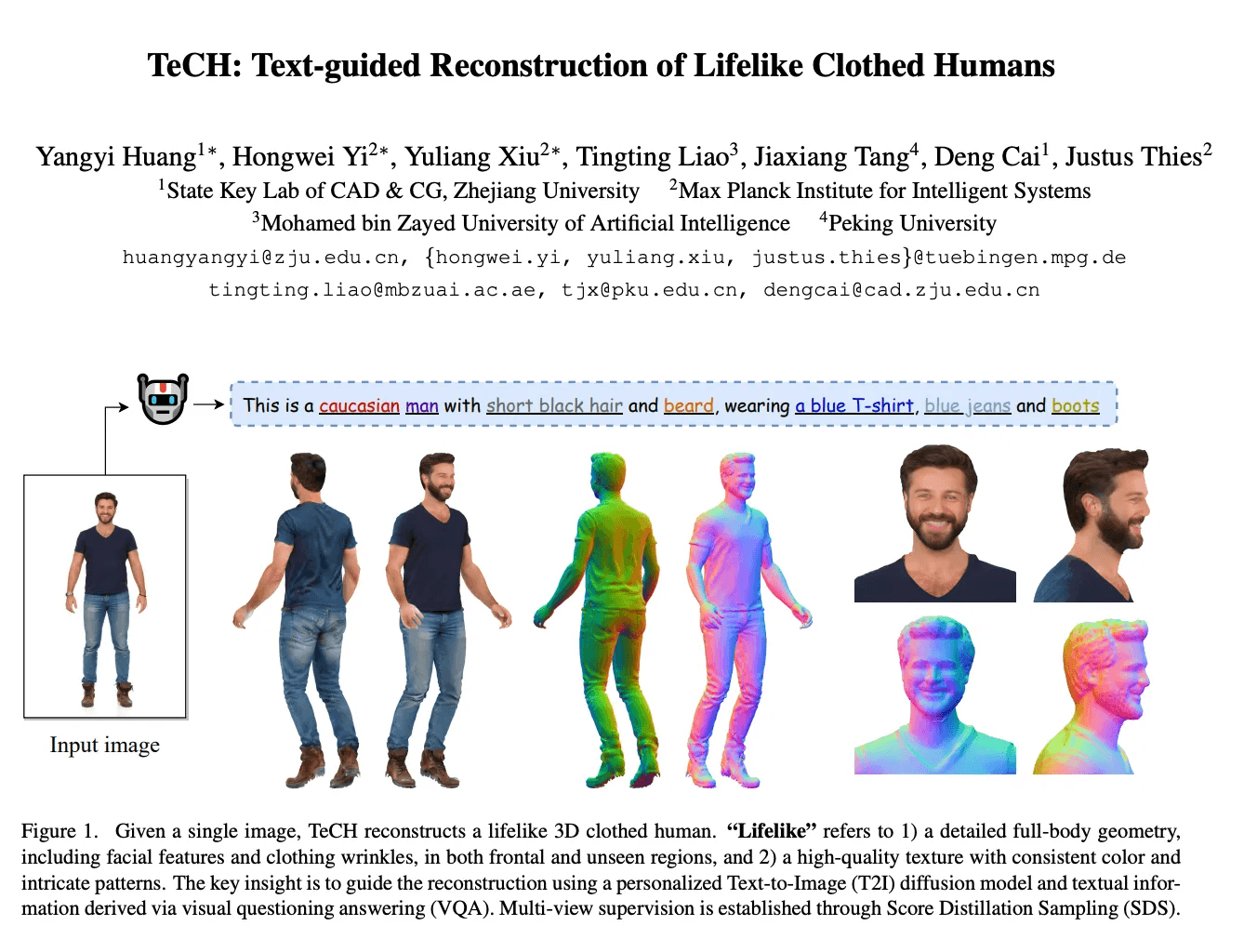
TeCH: 텍스트 가이드를 통한 실감 나는 3D 인간 재구성
문제점과 동기: 기존의 방법은 "보이지 않는 영역"의 고레벨 디테일을 정확하게 복원하는 데 실패하는 경우가 많음. TeCH는 기반 모델의 힘을 활용하여 이 문제를 해결하려고 함.
기술적 접근: TeCH는 자동으로 생성된 의복 파싱 모델과 시각적 질문 응답(VQA)을 통해 서술적인 텍스트 프롬프트(예: 의복, 색상, 헤어스타일)를 사용함. 이를 통해 "설명할 수 없는" 외모를 학습하는 개인화된 Text-to-Image 확산 모델(T2I)을 미세 조정함.
성능과 결과: TeCH는 일관되고 세밀한 텍스처와 자세한 전체 몸 형상을 가진 고해상도의 3D 복장을 입은 인간을 생성함. 양적 및 질적 실험은 TeCH가 재구성 정확도와 렌더링 품질 측면에서 최첨단 방법을 능가한다는 것을 보여줌.

글쓰기 교육에서 영감을 받은 개인화된 텍스트 생성을 위한 LLM 교육 방법
개인화된 텍스트 생성을 위한 새로운 방법론: 본 연구에서는 큰 언어 모델(LLMs)을 사용하여 개인화된 텍스트 생성을 위한 일반적인 접근법을 제안합니다.
글쓰기 교육에서 영감을 얻은 다단계, 다작업 프레임워크: 글쓰기 교육의 방법론을 따라 정보 검색, 평가, 요약, 통합 등의 다단계 프로세스를 구현합니다.
효과적인 결과와 다양한 기준선을 능가: 세 개의 공개 데이터셋에서 의 평가 결과, 기존의 다양한 기준선을 능가하는 성능 향상을 보였습니다.

SoTaNa 소개: 기존의 큰 언어 모델들인 ChatGPT와 LLaMa의 소프트웨어 엔지니어링 분야에서의 한계를 해결하기 위해 개발된 오픈 소스 소프트웨어 개발 보조 도구.
고품질 데이터와 파인튜닝: SoTaNa는 ChatGPT를 활용하여 고품질의 지시문 기반 데이터를 생성하고, 파라미터 효율적인 파인튜닝 방법을 사용하여 오픈 소스 기반 모델인 LLaMa의 능력을 향상시킴
평가와 접근성: SoTaNa의 Stack Overflow 질문에 대한 답변 능력과 코드 요약 및 생성 능력을 평가함. 모델은 단일 GPU에서도 실행 가능하여 더 넓은 범위의 연구자들에게 접근성이 좋음.
이번주 AI 프로덕트 📦

SeamlessM4T—대규모 다언어 & 멀티 모델 기계 번역
통합 번역 모델: SeamlessM4T는 최대 100개 언어를 지원하는 음성-음성, 음성-텍스트, 텍스트-음성, 텍스트-텍스트 등 다양한 종류의 번역을 할 수 있는 단일 모델.
데이터와 훈련: 100만 시간의 공개 음성 오디오 데이터와 406,000 시간의 인간 라벨링과 의사 라벨링 데이터를 사용하여 w2v-BERT 2.0을 통한 자기 지도형 음성 표현을 튜닝함.
성능 지표: 번역 품질에 대한 새로운 기준을 설정하며, 음성-텍스트와 음성-음성 번역에서 BLEU 점수에서 중요한 개선을 보임. 또한 배경 소음과 발화자 변동에 대한 강건성을 보이고, 번역에서 추가된 독성을 줄임.

AI2 Dolma: 3조 토큰으로 구성된 언어 모델용 데이터셋
데이터셋 크기와 내용: AI2의 Dolma는 웹 컨텐츠, 과학적 출판물, 코드, 책 등 다양한 출처로부터 3조 토큰을 모은 것이며, 현재까지 공개된 가장 큰 데이터셋.
언어 및 품질: Dolma는 대부분 영어 데이터로 구성되어 있으며, 미래 버전에서는 다른 언어를 포함할 계획임. 데이터셋은 중복, 저품질 내용, 민감한 정보가 제거되어 있음.
라이선스와 사용 조건: Dolma는 AI2의 ImpACT 라이선스 하에 중위험 아티팩트로 공개되었으며, 개인 데이터의 제거 요청을 처리할 수 있는 메커니즘이 마련되어 있음. 일부 비판자들은 라이선스에 너무 많은 조항이 있어 진정한 '오픈 소스'로 볼 수 없다고 주장함.
By BetaAI
© 2023