
1월 두번째 주 AI 뉴스
January 9, 2024

이번주 AI 뉴스 📰

OpenAI, 저작권 자료 없이는 ChatGPT 같은 AI 도구 개발 '불가능'
저작권 자료의 필요성: OpenAI는 ChatGPT 같은 AI 도구 개발에 저작권이 있는 자료의 접근이 필수적이라고 밝힘.
법적 도전과 대응: OpenAI와 Microsoft는 저작권 자료의 '불법 사용'으로 뉴욕 타임즈에 의해 고소당함.
AI 안전성과 협력: OpenAI는 독립적인 AI 안전성 분석을 지지하며, 강력한 모델의 안전 검사를 위해 정부와 협력하기로 함.

YouTube, AI로 제작된 실제 범죄 관련 딥페이크에 대한 단속 강화
정책 업데이트: YouTube가 사이버 괴롭힘 및 희생자 괴롭힘 정책을 갱신하며 범죄 피해자의 죽음이나 폭력을 사실적으로 재현하는 콘텐츠 금지.
피해자 가족들의 반응: AI로 제작된 어린이 목소리로 잔혹한 폭력을 묘사하는 콘텐츠에 대해 피해자 가족들이 '혐오스럽다'고 비판.
제재 및 규제: YouTube는 이러한 정책 위반 시 채널에서 콘텐츠를 삭제하고, 사용자의 플랫폼 이용을 제한하는 제재를 가할 예정.

Duolingo, AI 콘텐츠 확대로 계약직 10% 감축
AI 도입으로 인력 감축: Duolingo가 AI를 활용해 콘텐츠를 생성함에 따라 계약직의 약 10%를 감축.
AI의 다양한 활용: Duolingo는 언어 학습 쇼 스크립트 생성과 앱 내 음성 생성 등을 위해 AI를 사용하며, AI 피드백을 제공하는 프리미엄 서비스 도입.
AI의 노동 시장 영향: AI의 확대로 인해 노동 시장에 혼란이 예상되나, AI 기술을 활용할 수 있는 기술 인력에 대한 수요는 증가할 것으로 전망.
이번주 AI 논문 📝
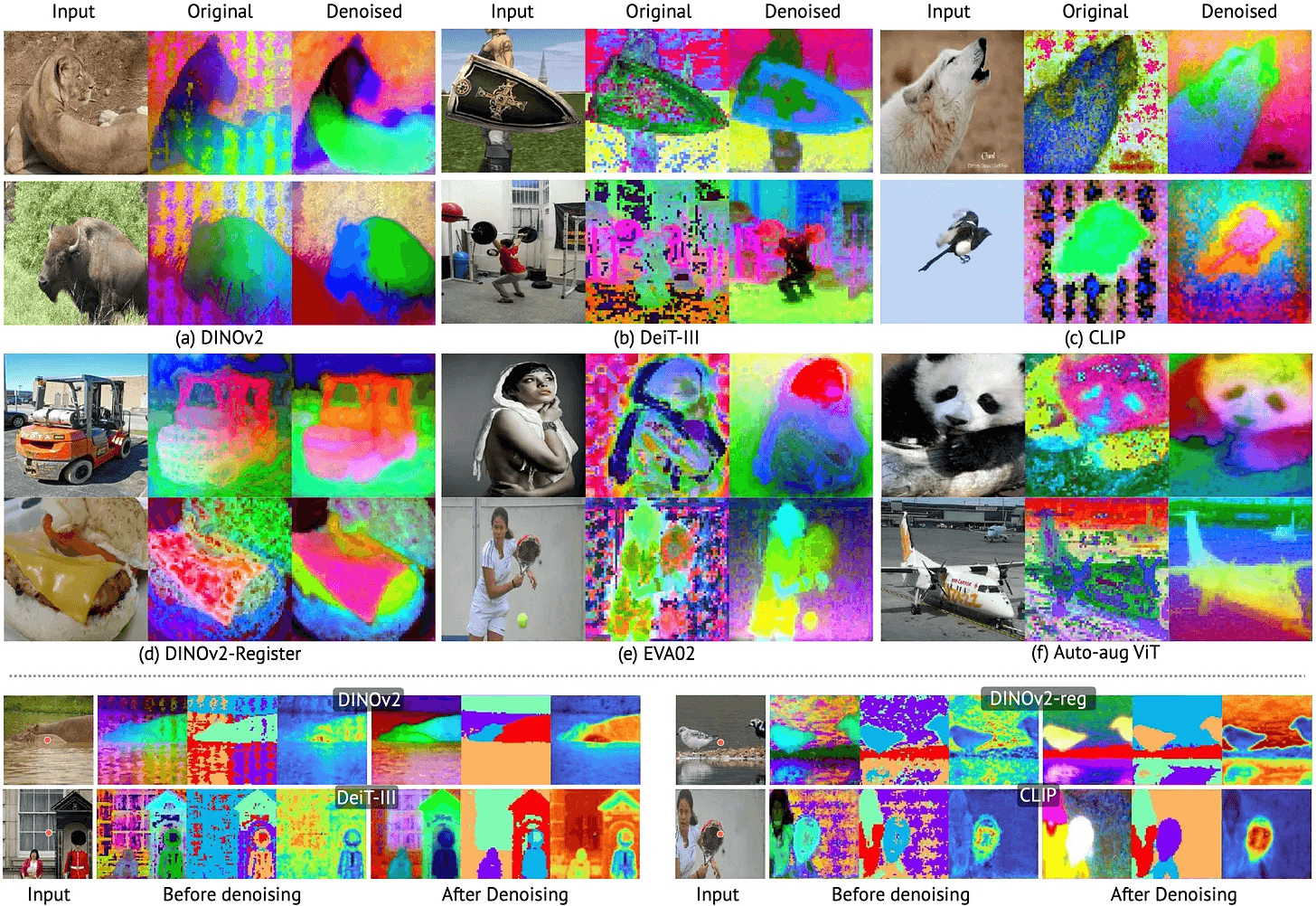
비전 트랜스포머의 결점: 위치 임베딩의 문제로 인해 비전 트랜스포머 모델의 특성 맵에서 그리드와 같은 아티팩트가 발생, 성능 저하의 원인.
새로운 잡음 모델 제안: 모든 비전 트랜스포머에 적용 가능한 새로운 잡음 모델을 통해 아티팩트 제거, 깨끗한 특성 추출.
효율적인 DVT 방법: 기존에 훈련된 비전 트랜스포머에 바로 적용 가능한 DVT 방법으로, 다양한 데이터셋에서 성능 향상 입증.

Open-Vocabulary SAM: 22,000가지 사물 인식 및 분할하는 모델
두 전문 도구 결합: CLIP(사물 인식 전문)과 SAM(이미지 내 사물 분할 전문)을 통합해, 이미지 내 특정 사물을 정확히 찾고 이를 인식하는 '오픈 어휘 SAM' 개발.
상호 학습 메커니즘: SAM은 CLIP로부터 사물 인식 방법을, CLIP은 SAM으로부터 사물의 정확한 위치 파악 방법을 배워 서로의 기능을 강화.
다양한 사물 인식 및 분할 성능 향상: 이 새로운 통합 모델은 약 22,000가지 다양한 카테고리의 사물을 인식하고 분할하며, 기존 도구들보다 월등히 높은 성능을 보임.

인간 선호도에 맞춘 대규모 언어 모델 'TeleChat' 기술 보고
대규모 언어 모델 개발: 3억, 7억, 12억 파라미터를 가진 대규모 언어 모델 'TeleChat' 소개, 영어와 중국어로 이루어진 광범위한 데이터셋에서 사전 훈련 데이터
인간 선호도 맞춤 튜닝: 인간의 선호도에 맞추어 세부적으로 조정된 방법론을 따라 모델을 튜닝하여 사용자와의 상호작용 개선.
다양한 분야에서 뛰어난 성능: 언어 이해, 수학, 추론, 코드 생성, 지식 기반 질문 답변 등 다양한 분야에서 유사한 크기의 다른 오픈 소스 모델과 비교하여 경쟁력 있는 성능 발휘.
이번주 AI 프로덕트 📦

음성에서 사실적인 아바타 생성: 대화 중 인간 모습 합성 기술
대화 기반 아바타 생성: 음성 데이터를 기반으로 얼굴, 몸, 손의 제스처를 포함한 사실적인 전신 아바타 생성.
다양한 표현력 강화 기술: 벡터 양자화의 샘플 다양성과 확산을 통한 고주파 세부 사항 결합으로 보다 역동적이고 표현력 있는 움직임 생성.
실제감 중요성 입증: 퍼셉츄얼 평가를 통해 대화 중 제스처의 미묘한 움직임을 정확하게 평가하는 데 아바타의 사실주의가 중요함을 강조.

효율적인 학습 목표: TinyLlama 프로젝트는 3조 토큰에 대해 1.1B Llama 모델을 사전 학습하는 것을 목표로 함.
호환성 및 컴팩트성: TinyLlama는 Llama 2와 동일한 아키텍처와 토크나이저를 사용, 호환성 및 컴팩트한 크기로 다양한 애플리케이션에 적용 가능.
빠른 학습 속도: 16개의 A100-40G GPU를 사용하여 90일 내에 학습을 완료할 계획.
By BetaAI
© 2023